
Experimenteller Aufbau eines Low-Cost High-VRAM LLM-Inferenzknotens: Eine Machbarkeitsstudie mit NVIDIA Tesla K80

Abstract
Ziel dieses Projekts war die Demonstration der technischen und finanziellen Machbarkeit eines lokalen Large Language Model (LLM)-Inferenzknotens mit einer VRAM-Kapazität von bis zu 120 GB unter Verwendung abgekündigter Server-Hardware. Der resultierende Tesla K80 PoC-Node (Kosten: ~ 945 € inkl. Kleinteile) erreicht eine nutzbare Gesamtkapazität von 90 GiB VRAM. Der experimentelle Fokus lag auf dem Vergleich der Datenqualität zwischen speicherbeschränkten (8B) und kapazitätsintensiven (120B) Modellen, wobei die Inferenzgeschwindigkeit gegenüber der VRAM-Kapazität keine Relevanz besitzt. Die Implementierung erforderte kundenspezifische Hardware-Modifikationen zur Stromversorgung und Kühlung der passiven Komponenten.
1. Systemübersicht und PoC-Zielsetzung 🎯
Das Hauptziel des Setups ist die Schaffung einer kostengünstigen Hardware-Plattform zur Erfahrungssammlung und zum Qualitätsvergleich großer Modelle (bis zu 120B Parameter). Das System dient als experimenteller Arbeitsplatz, nicht als produktive Inferenzlösung.
1.1 Kernkomponenten, Beschaffung und Limitationen
Insgesamt wurden fünf NVIDIA Tesla K80 Karten beschafft (vier über eBay und eine zusätzliche über Amazon), um die Kapazitätsziele des Projekts zu erreichen. Aufgrund der limitierten PCIe-Slots und der unzureichenden PCIe-Lanes des verwendeten B450-Chipsatzes konnten aktuell jedoch nur vier Karten in das System integriert werden, was die nutzbare Kapazität auf 90 GiB VRAM begrenzt.

PCIe-Topologie als Flaschenhals: Der B450-Chipsatz stellt einen kritischen Flaschenhals dar. Die Anbindung der vier K80-Karten ist stark limitiert (über PCIe 3.0 x16, x4 und x1-Links), was die Inter-GPU-Kommunikation für das Modell-Sharding und die gesamte Modell-Ladezeit (Load Duration) stark beeinflusst.
Nächstes Upgrade-Ziel (144 GiB): Das nächste Ziel des Projekts ist die Beschaffung eines Mainboards mit mindestens sechs PCIe-Slots und den notwendigen Lanes, um sechs K80-Karten (entspricht 12 unabhängigen GK210-GPUs) zu verbauen. Dies soll die geplante Zielkapazität von theoretischen 144 GiB VRAM erreichen, wobei die nutzbare Kapazität voraussichtlich bei ~135 GiB liegen wird (unter Berücksichtigung des ECC-Overheads).
- Mainboard-Kandidaten (Budget-Vorschläge): Für dieses Aufrüstungsziel eignen sich ältere Workstation-Plattformen wie AMD Threadripper (TR4) oder Intel X-Serie (LGA 2011/2066) Mainboards, da diese über eine höhere Anzahl an PCIe-Lanes verfügen.
| Komponente | Spezifikation | Einzelpreis | Gesamtkosten (Verbaut) | Referenz / Bezugsquelle |
| GPU-Array (Verbaut) | 4x NVIDIA Tesla K80 (8x GK210) | 63,75 € / 89,00 € | ~ 255,00 € | eBay Angebots-Link / Amazon Link |
| GPU-Array (Total Beschafft) | 5x NVIDIA Tesla K80 (10x GK210) | – | ~ 344,00 € | – |
| CPU | AMD Ryzen 5 5600G | 121,90 € | 121,90 € | AMD Produktseite |
| Mainboard | Gigabyte B450 AORUS ELITE V2 | 88,90 € | 88,90 € | Gigabyte Produktseite |
| RAM | 64 GB G.Skill DDR4-3200 (2x 32 GB) | 68,90 € | ~ 137,80 € | – |
| SSD | 1 TB Intenso M.2 NVMe SSD | – | ~ 50,00 € | Amazon Link |
1.2 Produktive Infrastruktur (Referenz)
Für den produktiven Einsatz wird ein separater RTX-Node verwendet, der mit 18 GB VRAM schnelle Inferenzraten für kleinere Modelle wie gpt-oss:20b bietet.
2. Hardware-Implementierung und Thermisches Management ⚡️❄️
2.1 Architektonische Visualisierung (Dual-Chassis & Dual-PSU)
Die Komplexität des Aufbaus ergibt sich aus der Notwendigkeit, das Host-System vom dedizierten GPU-Power- und Kühlungs-Setup zu trennen.
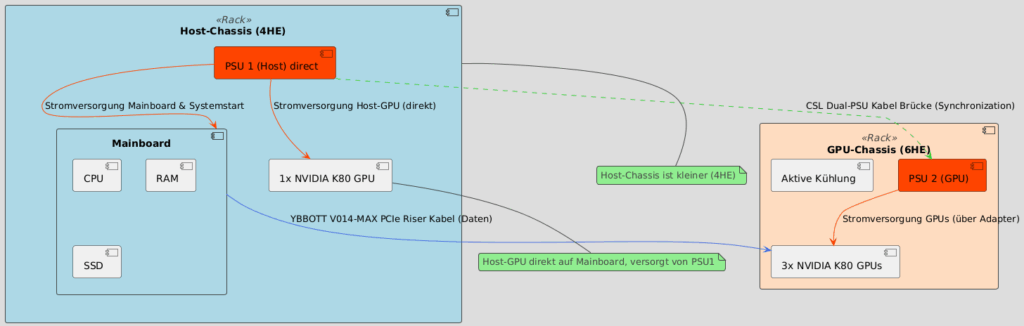
Architektur-Schema für Visualisierung:
- Host-Chassis (4HE): Beinhaltet CPU, Mainboard, RAM, SSD, 1x K80-Karte und PSU 1 (Host).
- GPU-Chassis (6HE): Beinhaltet die 3x K80-Karten, die aktive Kühlungs-Hardware und PSU 2 (GPU).
- Logische Trennung der Stromversorgung: PSU 2 (GPU) versorgt ausschließlich die 3 K80-Karten. Die [CSL Dual-PSU Kabel Brücke] synchronisiert PSU 1 und PSU 2.
| Komponente | URL | Funktion und Nutzen |
| GPU-Riser | YBBOTT V014-MAX PCIe Riser | Ermöglicht die Verbindung der Grafikkarten im separaten GPU-Gehäuse mit dem Mainboard. |
| Adapterkabel | 8 Pin CPU zu 8 Pin PCIe (K80) | Löst das Steckerproblem der K80-Karten (die 8-Pin-CPU-Anschlüsse benötigen). |
| Dual PSU Kabel Brücke | CSL Dual-PSU Kabel Brücke | Synchronisiert den Start beider Netzteile. |
| Netzteil 1 (Host) | Thermaltake Smart BM2 (1200W Variante) | Primäre PSU für Kernkomponenten und eine K80-Karte |
| Netzteil 2 (GPUs) | Mars Gaming MPB1000 | Dedizierte 1000W für die drei K80-Karten. |
2.2 Aktives Thermal-Management & Energieeffizienz

Zur Vermeidung thermischer Drosselung musste die passive Kühlung durch eine aktive Zwangskühlung ersetzt werden.
- Adapter: 3D-gedruckte Adapter (Thingiverse-Link) wurden zur Montage von Lüftern direkt an den K80-Kühlkörpern verwendet.
- Lüfter: ARCTIC S8038-7K Server FAN (Hochleistung).
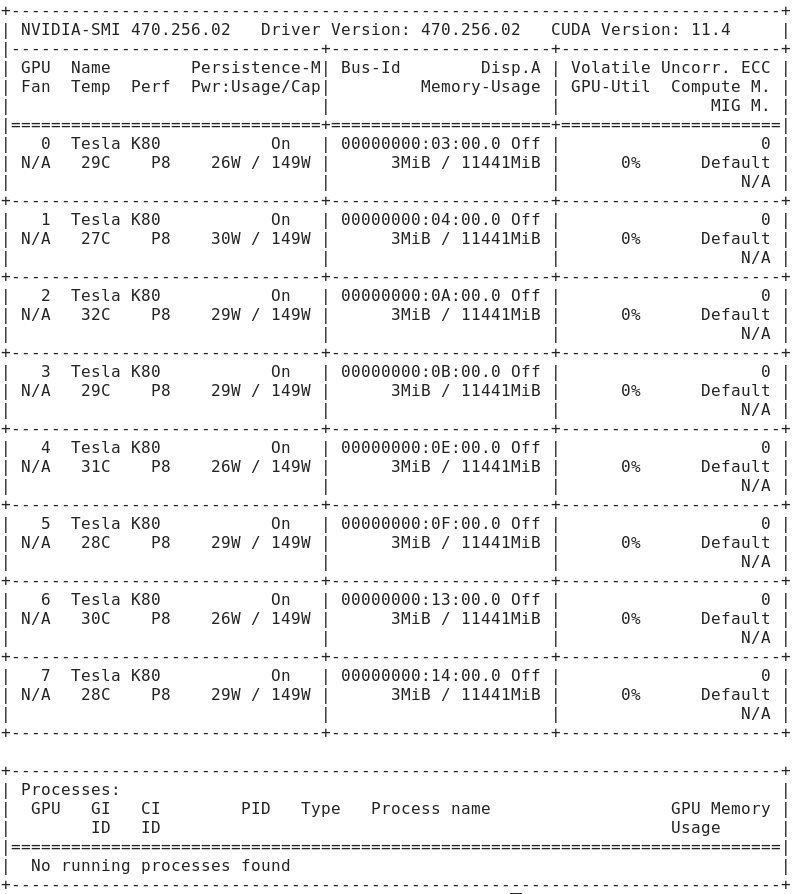
- Temperatur unter Last: Diese Lösung hält die 8 GPUs unter Last bei stabilen 65 °C, womit die thermische Drosselung überwunden ist.
- Effizienz-Tipp (TDP-Capping): Jede K80 hat eine Nenn-TDP von 300 W. Der Idle-Verbrauch liegt bei ∼30W pro GPU. Das Power Limiting mittels nvidia-smi -i <gpu_id> -pl <limit> (z.B. auf 200W) kann zur Senkung der Betriebskosten angewendet werden, oft mit nur moderaten Leistungseinbußen.
3. Methodik und Leistungsanalyse 📊
3.1 Software-Stack, CUDA und Kompatibilität
| Container | Funktion | Schnittstelle / Repository |
| Ollama 3.7 | LLM Runtime (Backend) | GitHub Repository |
| Open-WebUI | Frontend für Inferenz und Administration | Open WebUI GitHub |
Kritische Kompatibilitätshinweise: Die K80 basiert auf der Kepler-Architektur und bietet eine CUDA Compute Capability (CC) von 3.5/3.7. Dies schränkt die Auswahl moderner Frameworks ein (viele benötigen CC 5.0+). Zudem ist das System an Ubuntu 20.04 LTS gebunden, da der verwendete NVIDIA-Treiber 4.70 in höheren Ubuntu-Versionen nicht mehr stabil unterstützt wird.
3.2 VRAM-Kapazität, Lastverteilung und Optimierung
VRAM-Differenz: Die theoretische Brutto-Kapazität beträgt 96 GiB. Die nutzbare Netto-Kapazität von 90 GiB resultiert aus dem ECC-Overhead (Error-Correcting Code) und Systemreserven.
Multi-GPU-Sharding:
- Datenaustausch-Engpass: Die K80 unterstützt kein NVLink (oder vergleichbares schnelles Interconnect). Der gesamte Datenaustausch zwischen den 8 GK210-Chips für das Tensor Parallelism muss ausschließlich über den langsamen PCIe-Bus erfolgen, was den Overhead drastisch erhöht und die niedrige Inferenzrate erklärt.
- Ladezeit-Anomalie: Die schnellere Modell-Ladezeit (26.62s vs. 33.56s des RTX-Nodes) wird hypothetisch durch die parallele I/O-Fähigkeit der 8 unabhängigen GK210-Chips erklärt, welche das Modell gleichzeitig in ihre 12 GiB-Speichersegmente laden.
Optimierung durch Quantisierung:
- Die Strategie maximiert die Kapazität durch Quantisierungstechniken (z.B. GGUF auf 4-Bit). Dies ermöglicht das Laden und Vergleichen von Modellen bis zu 180B+ (im Gegensatz zu unquantisiert, wo 240 GiB nötig wären).
3.3 Experimentelle Ergebnisse (Geschwindigkeits- vs. Kapazitätsanalyse)
Der Benchmark dient primär zur Verdeutlichung der Geschwindigkeits- vs. Kapazitäts-Kosten im LLM-Umfeld.
Test-Szenario: LLM gemma3:12b mit identischem Prompt.
| Metrik | K80 PoC-Node (8x GK210, 90 GiB VRAM) | RTX Produktions-Node (RTX 3060/1060, 18 GiB VRAM) | Verhältnis |
| Token-Generierungsrate (tokens/s) | 4.17 | 30.09 | 7.2x schneller (RTX) |
| Prompt-Verarbeitungsrate (tokens/s) | 4.29 | 33.56 | 7.8x schneller (RTX) |
| Gesamtdauer | 121.71 Sekunden | 48.81 Sekunden | RTX 2.5x schneller |
| Modell-Ladezeit | 26.62 Sekunden | 33.56 Sekunden | K80 6.9s schneller |
Detailliertere Benchmarks und Vergleiche der Hardware-Leistung finden Sie auf meiner weiteren Domain: unter llm-gpu-benchmark.self-hosted.app.
4. Schlussfolgerung
Der Tesla K80 PoC-Node beweist, dass es möglich ist, mit einem geringen Budget eine LLM-Hardware-Plattform mit hoher VRAM-Kapazität aufzubauen, um Forschungsfragen zur Datenqualität und Modellauswahl zu adressieren, die andernfalls hochpreisige, moderne Serverhardware erfordern würden. Die technischen Herausforderungen des thermischen und Power-Managements sowie der Kompatibilität wurden durch pragmatische Lösungen erfolgreich gelöst.
Preprint zu diesem Projekt als PDF unter https://philipp-horn.dev/wp-content/uploads/2025/09/Preprint-Tesla-K80-GPU-Node.pdf